
Contourner les défis de l’analyse cellulaire haut contenu grâce à l’IA/apprentissage machine
L’intelligence artificielle (IA) est présente dans de nombreux aspects de la vie moderne, des véhicules autonomes aux assistants personnels à commande vocale, et même dans la création artistique. Mais c’est dans l’application de la science et des soins de santé que les avantages de l’IA se distinguent vraiment. L’une de ces applications est l’analyse de bioimages ou l’analyse haut contenu (HCA).
Alors que l’HCA est devenue mature et de plus en plus adoptée comme outil quantitatif pour la recherche biomédicale, l’espace d’application continue à se développer et n’est plus limité à une liste limitée de tests bien définis réalisés dans des modèles biologiques standard. Pour tenir compte de cette complexité supplémentaire, l’accent a été mis sur l’amélioration de la flexibilité et des performances des méthodes d’analyse par l’IA ou l’apprentissage machine. En fait, il existe de nombreux exemples où il surpasse les méthodes traditionnelles pour les applications dans de nombreuses disciplines scientifiques.
Jusqu’à récemment, l’utilisation de ces méthodes d’apprentissage machine plus sophistiquées a été largement réservée aux groupes de recherche qui ont un accès adéquat aux compétences spécialisées en science des données et au développement de logiciels personnalisés. Ici, nous présentons brièvement l’IA et nous explorons comment les solutions logicielles d’apprentissage machine clés en main émergentes permettent aux chercheurs d’exploiter tout le contenu d’une image et de réaliser une analyse plus complète, tout en éliminant la charge de complexité pour l’utilisateur.
Qu’est-ce que l’IA ou l’apprentissage machine ?
L’apprentissage machine est une forme d’IA (intelligence artificielle). Apprentissage profond. Réseaux neuronaux. Ce sont tous des termes légèrement différents pour l’IA, que le dictionnaire d’Oxford définit comme suit :
« La théorie et le développement de systèmes informatiques capables d’effectuer des tâches nécessitant normalement l’intelligence humaine, telles que la perception visuelle, la reconnaissance vocale, la prise de décision et la traduction entre les langues. »
En fait, l’IA représente toute intelligence démontrée par des machines qui imitent les fonctions cognitives que nous associerions généralement aux esprits humains, comme l’apprentissage, la résolution de problèmes et le raisonnement. L’apprentissage machine est une technique utilisée par les chercheurs pour permettre aux ordinateurs d’apprendre rapidement des données.
Surmonter les complexités d’un flux de travail HCA
À la base, un criblage haut contenu ou flux de travail HCA, comme notre ImageXpress Confocal HT.ai, n’est rien de plus que la microscopie automatisée suivie d’une analyse d’images automatisée. Pendant l’étape d’acquisition, les images sont acquises à partir de plusieurs échantillons dans des microplaques. Cela peut impliquer de recueillir une grande quantité de données d’images si vous essayez de comprendre, par exemple, un médicament efficace pour sauver certains phénotypes malades.
La partie analyse du flux de travail peut être divisée en deux parties : l’analyse d’images et l’analyse en aval. Pendant l’analyse d’images, certaines caractéristiques et mesures sont extraites de l’image et converties dans un format dans lequel l’analyse statistique peut être appliquée. L’analyse en aval implique de prendre toutes les données à haute dimension et de les distiller dans un format que les scientifiques peuvent interpréter et tirer des conclusions afin de pouvoir passer à la phase suivante de leur projet de recherche.
Le monde actuel du criblage haut contenu est beaucoup plus complet lorsqu’il s’agit de comprendre et de décrire un phénotype. Au lieu d’extraire une seule caractéristique ou de prendre un rapport de mesures différentes, les chercheurs extraient des milliers de caractéristiques pour chaque cellule d’une image. Cela ne nécessite pas qu’ils sachent quelle est la cible d’un médicament ou qu’ils comprennent parfaitement la fonction d’un gène. Il s’agit simplement de chercher des différences entre deux conditions différentes en exploitant tous les contenus riches en informations de l’image.
Comme la complexité de certains tests ne cesse d’augmenter et que nous extrayons davantage d’informations d’une cellule individuelle, les données deviennent encore plus accablantes. Alors, comment pouvons-nous donner du sens à toutes ces informations et les résumer à quelque chose qui est exploitable ?
Les méthodes traditionnelles d’analyse d’images peuvent être particulièrement complexes et fastidieuses lorsqu’elles sont réalisées manuellement ou même semi-automatiquement. Il existe toujours une possibilité d’erreur humaine et de biais en raison de la nature difficile et extrêmement détaillée de la tâche. Si vous ajoutez à cela la nature répétitive, longue et souvent laborieuse du flux de travail, l’apprentissage machine entre en jeu. L’IA élimine toute variation d’une personne à l’autre, toute erreur humaine et tout biais, améliorant ainsi la qualité et la confiance des données, ainsi que l’optimisation du flux de travail et de l’efficacité.
Surmonter les préjugés humains
L’un des principaux avantages de l’apprentissage machine dans le HCA qui mérite une note spéciale est la capacité à surmonter les biais humains. Lors de l’étude de grands ensembles de données, les humains sont vulnérables à un phénomène bien décrit appelé « cécité inattentionnelle ». C’est là que des observations inattendues passent inaperçues lors de l’exécution d’autres tâches nécessitant de l’attention.
Par exemple, après avoir étudié un phénotype et une réponse cellulaires particuliers en détail, vous pourriez rechercher involontairement ces mêmes signes lorsqu’un vaste ensemble de données complexes contenant de nombreuses variables et mesures est présenté. Ce faisant, vous pourriez alors ignorer une autre caractéristique subtile ou inattendue qui a également une pertinence biologique.
L’apprentissage machine aide à surmonter cette faille, en réalisant une classification totalement objective, avec le potentiel de produire des résultats inattendus et précieux.
Application de l’apprentissage machine à la segmentation d’objet
Des données quantitatives fiables sont vitales pour chaque étape aval du flux de travail HCA, la segmentation étant la première. La segmentation est le processus d’extraction des objets d’intérêt (ex. : organites) des images, puis de quantification de leurs caractéristiques. Fondamentalement, c’est la première étape pour convertir les pixels d’images en données numériques.
La segmentation peut être difficile, en particulier lorsque vous travaillez avec des méthodes traditionnelles de traitement du signal, qui sont conçues pour se concentrer sur un objet. Sur les images microscopiques de cellules ou de tissus, les objets sont généralement encombrés ou amassés. De plus, ils ont des tailles et des formes différentes. Il y a souvent le problème d’un mauvais rapport signal/bruit, d’un faible contraste et d’une mauvaise résolution de l’image. Sans oublier qu’il peut y avoir une variabilité phénotypique élevée en raison de perturbations chimiques ou d’une hétérogénéité naturelle dans le type de cellule lui-même.
Pour relever les défis de la segmentation, des algorithmes d’apprentissage profond peuvent être appliqués à la partie analyse d’images du flux de travail HCA. Par exemple, le logiciel d’analyse d’images IN Cartaκ inclut un module d’apprentissage profond appelé SINAP, conçu pour fonctionner avec un large éventail de données.
Comme SINAP utilise l’apprentissage profond, il peut prendre en compte de grandes quantités de variabilité dans l’apparence de l’échantillon qui découlent des traitements à l’étude. En s’assurant que chaque traitement est segmenté avec un niveau de précision équivalent, les informations extraites dans cette étape peuvent être utilisées de manière fiable pour comparer les traitements dans les étapes suivantes de l’analyse.
Exemples de module IN Carta SINAP utilisé :
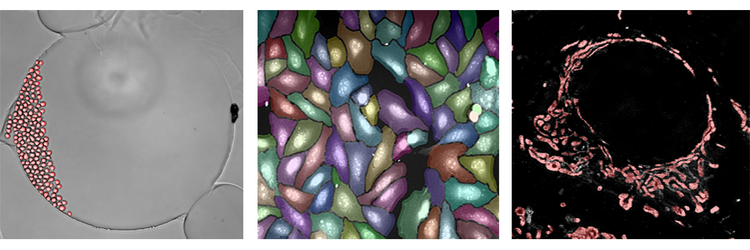
Vous trouverez ci-dessus des exemples de l’algorithme d’apprentissage profond SINAP appliqué à trois ensembles de données totalement différents. L’analyse en fond clair est illustrée dans la figure de l’extrême gauche. L’analyse consiste en réalité à segmenter des cellules uniques dans le temps, en observant les cellules vivantes se diviser et se déplacer. La figure du milieu montre la segmentation d’un test de marquage cellulaire. Même si les cellules sont encombrées, SINAP est capable de segmenter les objets avec une grande précision. Enfin, la figure à l’extrême droite est issue d’une image en super résolution des mitochondries. Une fois encore, même si ce contenu est complètement différent, le même flux de travail et l’algorithme peuvent être utilisés pour étudier les mitochondries individuelles dans les sources de données et l’image. Dans les trois cas, vous pouvez réaliser facilement une segmentation de manière plus précise et fiable à l’aide de l’algorithme d’apprentissage profond SINAP.
Application de l’apprentissage machine à la classification des objets
Comme vous essayez d’exploiter autant de contenu que possible dans un flux de travail HCA, il est important de vous assurer que le contenu a un certain degré de qualité avant d’atteindre l’étape d’analyse en aval. C’est là que la classification des objets entre en jeu. La classification d’objets est le processus consistant à diviser les ensembles de données en sous-populations en fonction du phénotype (p. ex., morphologie cellulaire, localisation subcellulaire, niveau d’expression de marqueurs spécifiques).
Il est possible d’utiliser un classificateur pour sélectionner manuellement des caractéristiques pertinentes et attribuer des classes, mais cela ne s’applique qu’aux modifications phénotypiques simples basées sur quelques mesures. Par exemple, vous pouvez déterminer une étape du cycle cellulaire en fonction de l’intensité du colorant nucléaire ou classer les cellules vivantes ou mortes dans un test de viabilité. Pour tout ce qui est plus complexe impliquant un ensemble étendu de caractéristiques, l’utilisation de l’IA pour la classification des objets devient une meilleure option.
Avec l’apprentissage machine, l’utilisateur humain n’a plus besoin de sélectionner manuellement des mesures ou des seuils. Cette tâche est plutôt attribuée à l’ordinateur. L’utilisateur humain fournit des exemples informatiques de différentes classes de cellules. L’ordinateur sait comment différencier ces classes. En substance, l’ordinateur apprend les caractéristiques les plus appropriées et a l’avantage supplémentaire qu’il peut apprendre la bonne combinaison de caractéristiques.
Le logiciel IN Carta comprend également un module de classificateur de niveau d’objet pouvant être entraîné appelé Phenoglyphs. Le module Phenoglyphs utilise les informations extraites par SINAP pour regrouper des objets ayant une apparence visuelle similaire. Ce faisant, on peut évaluer si un traitement génère un phénotype favorable et même déduire les mécanismes sous-jacents impliqués. En utilisant l’apprentissage machine, toutes les caractéristiques visuelles peuvent être analysées simultanément afin d’optimiser l’ensemble complexe de règles nécessaires pour affecter les objets à leur groupe approprié. Cette approche très multivariée et axée sur les données est beaucoup plus à même de résoudre les différences phénotypiques subtiles et est plus robuste pour l’attribution d’objets à un groupe incorrect.
Les quatre étapes de la formation au module IN Carta Phenoglyphs :
- Groupe : Le module sélectionne et utilise automatiquement des mesures calculées pendant la segmentation pour créer des regroupements naturels dans les données, appelés groupes, sans biais humain.
- Étiquette : L’utilisateur sélectionne et étiquette toutes les classes valides (au moins deux) pour le classement et l’entraînement.
- Classement : Le module classe la liste des mesures utilisées pour diviser les objets en classes et offre la possibilité de désélectionner les mesures avec des informations redondantes ou peu d’impact.
- Formation : Le module affine le modèle de classification en fonction de la saisie de l’utilisateur, y compris la suppression d’objets ou la réaffectation à des classes plus appropriées.
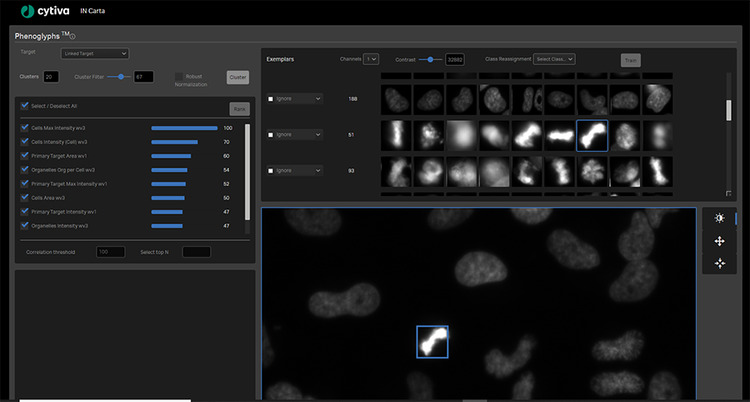
Formation au module de classification de l’apprentissage machine Phenoglyphs
En tant qu’utilisateur, il vous suffit de revoir et de fournir des données sur un petit nombre d’exemples pour chaque classe avant que le module Phenoglyphs applique le modèle à l’ensemble des données. Cette approche minimise le besoin de saisie de l’utilisateur lors de la première étape de l’attribution de la classe, ce qui permet de gagner un temps considérable.
Élimination des conjectures
Le logiciel IN Carta est l’étape initiale sans surveillance intégrée aux modules SINAP et Phenoglyphs. L’étape sans surveillance génère un résultat initial qui est optimisé de manière itérative simplement en demandant à l’utilisateur de confirmer ou de corriger la décision de l’algorithme. Cela élimine le fardeau de la détermination d’un point de départ viable pour l’analyse et la nécessité de modifier les paramètres de manière fastidieuse et erronée. En combinant SINAP et Phenoglyphs, les utilisateurs bénéficient d’un flux de travail complet qui ne nécessite aucune expérience préalable en matière d’analyse d’images ou d’analyses statistiques et qui est rationalisé pour un délai d’obtention des résultats plus court.
En savoir plus sur l’optimisation de votre flux de travail HCA avec l’apprentissage machine. Voir notre page du logiciel IN Carta.