
Outils d’IA, d’apprentissage machine et d’apprentissage profond pour l’analyse d’images cellulaires
Intelligence artificielle dans les flux de travail automatisés d’analyse d’images
L’adoption récente des méthodes d’apprentissage machine, approche permettant d’atteindre l’intelligence artificielle (IA), dans l’analyse d’images gagne rapidement du terrain dans de nombreux domaines de recherche. L’apprentissage profond fait partie d’un algorithme d’apprentissage machine basé sur un réseau neuronal artificiel. L’architecture de l’apprentissage profond a résolu avec succès des problèmes d’analyse complexes dans des applications d’imagerie médicale, de pathologie et de biologie.
Définition des termes de l’IA :
Intelligence artificielle (IA) – Simulation de processus d’intelligence humaine par des systèmes informatiques.
Apprentissage automatique (machine learning, ML) – Approche pour atteindre l’IA en utilisant des algorithmes afin de déterminer ou de prédire des modèles basés sur des données existantes. Les algorithmes d’apprentissage machine déduisent ensuite automatiquement les règles permettant de distinguer les classes.
Apprentissage profond (deep learning, DL) – sous-ensemble des méthodes d’apprentissage automatique (machine learning) qui utilisent des réseaux neuronaux convolutifs (CNN) pour apprendre les relations d’entrée/sortie. Les CNN sont des modèles mathématiques représentés par plusieurs couches de « neurones » ou cellules computationnelles.
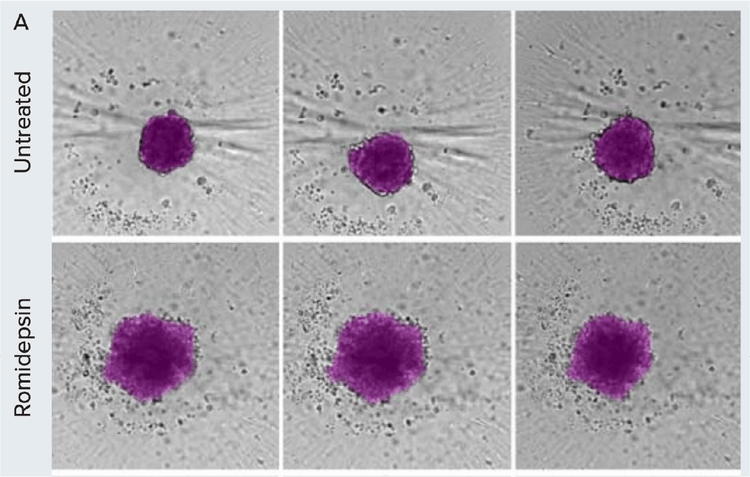
Analyse morphométrique du traitement de composés sur des sphéroïdes dérivés de patients dans le temps. A) Les sphéroïdes ont été suivis par imagerie en fond clair les jours 1, 3 et 5 post-traitement. Les images ont été segmentées en utilisant SINAP dans le logiciel IN Carta (superposition magenta).
L’apprentissage machine améliore la segmentation des images et la classification des objets
L’analyse automatisée d’images fait partie intégrante de la plupart des plateformes d’imagerie haut contenu. La capacité à surveiller les cellules et les organoïdes en temps réel et à en extraire des informations significatives dépend d’une analyse robuste des images de lumière transmise sans marquage. Les difficultés associées à l’analyse des images en fond clair comprennent le faible contraste, le bruit de fond irrégulier et les artefacts d’imagerie. Un ensemble défini de paramètres globaux ne réussit que rarement à segmenter des objets évalués par imagerie en fond clair. Les avancées récentes de l’apprentissage machine améliorent le flux de travail de l’analyse d’images et permettent une segmentation plus robuste des images dans des ensembles de données complexes.
Dans l’analyse des images biologiques, l’apprentissage profond fournit une boîte à outils puissante pour s’attaquer à la segmentation des images et au suivi des objets. L’analyse d’images traditionnelle implique généralement la définition d’un ensemble fixe de paramètres pour segmenter les objets d’intérêt en vue d’une quantification en aval. Cependant, ces paramètres prédéfinis ne fonctionnent pas pour toutes les expériences en raison de la grande variabilité des conditions expérimentales. Les ajustements manuels du protocole d’analyse ne sont pas pratiques en raison de l’énorme volume de données d’imagerie dans un environnement haut débit.
Pour surmonter ces difficultés, des outils d’apprentissage machine peuvent être utilisés pour la segmentation des images et la classification des objets afin d’automatiser le flux de travail d’analyse d’images.
Logiciel d’analyse d’images IN Carta pour l’analyse haut débit basée sur l’apprentissage machine

Le logiciel d’analyse d’images IN Carta® offre une interface utilisateur intuitive qui inclut des outils d’IA dans le flux de travail d’analyse d’images. Les modules logiciels SINAP et Phenoglyphs sont deux éléments clés du logiciel IN Carta qui exploitent l’apprentissage machine. Le SINAP basé sur l’apprentissage profond permet une détection robuste d’objets d’intérêt complexes (par exemple, colonies de cellules souches ou organoïdes) avec une intervention humaine minimale pour améliorer la précision et la fiabilité de la première étape de l’analyse d’images. Le résultat de l’analyse comprend des mesures morphologiques, d’intensité et de texture.
La classification des données peut également être utilisée avec Phenoglyphs basé sur l’apprentissage machine. Phenoglyphs prend des centaines de descripteurs d’images extraits par SINAP et crée un ensemble optimal de règles pour regrouper les objets ayant une apparence visuelle similaire. Les deux modules utilisent des décisions non supervisées pour générer un résultat initial que vous optimisez de manière itérative par vos entrées utilisateur. Ensemble, ils améliorent l’intégrité et la précision des résultats grâce à un flux de travail complet et facile à utiliser.
Appliquez l’apprentissage profond à la segmentation d’objets grâce à IN Carta SINAP
La segmentation automatique des objets dans les images de microscopie peut s’avérer difficile en raison de la nature diverse des ensembles de données. Le logiciel d’analyse d’images IN Carta utilise SINAP, un module de segmentation pouvant être entraîné et utilisant un algorithme d’apprentissage par réseau neuronal convolutionnel profond pour résoudre ces problèmes difficiles.
Comme SINAP utilise l’apprentissage profond, il peut tenir compte de la variabilité importante de l’apparence des échantillons qui découle des traitements test étudiés. En s’assurant que chaque traitement est segmenté avec un niveau de précision équivalent, les informations extraites à cette étape sont fiables et utiles pour comparer les traitements dans les étapes d’analyse suivantes.
Surmonter les difficultés de la segmentation d’images avec des modèles basés sur l’apprentissage machine :

A) Nous présentons des exemples de différents modèles biologiques qui posent des problèmes d’analyse quantitative. Les sphéroïdes 3D mis en culture dans des plaques à microcavités produisent une ombre autour de chaque microcavité qui interfère avec la segmentation des objets (flèche). Les organoïdes 3D sont mis en culture dans du Matrigel, ce qui produit souvent un bruit de fond non homogène en raison de la distorsion du dôme de Matrigel et des objets situés au-delà des plans d’imagerie (encadré). Les iPSC se développent sous forme de cultures relativement plates ; par conséquent, le faible contraste (flèche bleue) et les débris (flèche jaune) empêchent une segmentation robuste des images des colonies d’iPSC.
B) Vue d’ensemble du flux de travail de l’apprentissage de modèle : Générer des images pour l’apprentissage > Former le modèle > Tester le modèle > Répéter.
C) Principales étapes de la création d’un modèle dans le logiciel IN Carta à l’aide de SINAP, avec des exemples d’images présentés. Les images sont annotées à l’aide d’outils de marquage pour indiquer les objets d’intérêt et le bruit de fond. L’image annotée représentant la situation réelle est ajoutée à l’ensemble d’apprentissage. Lors de l’étape d’apprentissage, un modèle est créé sur la base du modèle existant qui convient le mieux et des annotations spécifiées par l’utilisateur. Dans l’exemple présenté, il est nécessaire de corriger le masque de segmentation (étape 3), en répétant les étapes 1 à 3.
Appliquer l’apprentissage machine à la classification des objets avec IN Carta Phenoglyphs
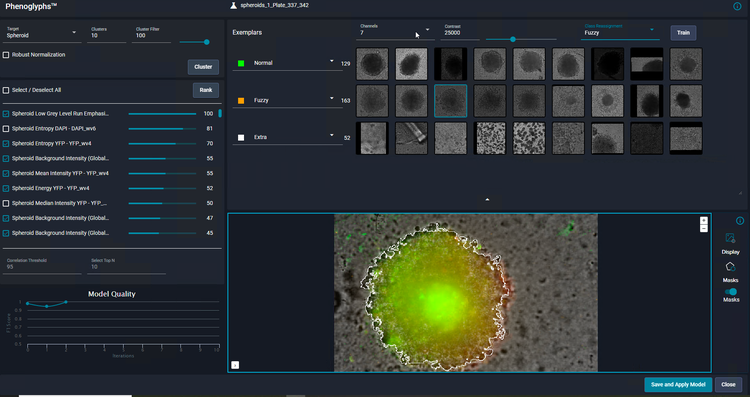
En tant qu’utilisateur, il vous suffit de revoir et de fournir des données sur un petit nombre d’exemples pour chaque classe avant que le module Phenoglyphs applique le modèle à l’ensemble des données. Cette approche réduit le besoin de contribution de l’utilisateur à la première étape d’une affectation de classe, ce qui permet de gagner un temps considérable.
Applications basées sur l’apprentissage machine
Les méthodes traditionnelles d’analyse d’images peuvent être incroyablement complexes et fastidieuses lorsqu’elles sont réalisées manuellement ou même de manière semi-automatique. Il y a toujours un risque d’erreur humaine et de partialité en raison de la nature complexe et très détaillée de la tâche. Si vous ajoutez à cela la nature répétitive, longue et souvent laborieuse du flux de travail, l’apprentissage machine entre en jeu.
Découvrez comment le logiciel d’apprentissage profond d’IN Carta associé au système ImageXpress HCS.ai a permis d’éliminer les variations d’une personne à l’autre, les erreurs humaines et les biais, améliorant ainsi la qualité et la fiabilité des données et optimisant le flux de travail et l’efficacité.